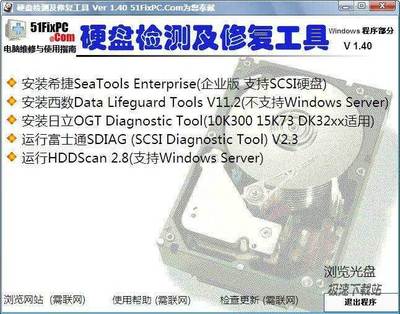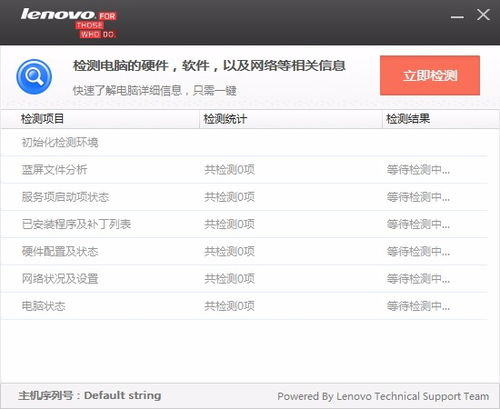
聯(lián)想電腦檢測(cè)軟件是一款專為聯(lián)想品牌計(jì)算機(jī)設(shè)計(jì)的實(shí)用工具,版本 v1.0.0.3 官方版確保了軟件的穩(wěn)定性和安全性。該軟件旨在幫助用戶快速檢測(cè)電腦硬件狀態(tài)、系統(tǒng)性能及潛在問(wèn)題,從而提升設(shè)備的使用壽命和效率。
要下載聯(lián)想電腦檢測(cè)軟件 v1.0.0.3 官方版,建議訪問(wèn)聯(lián)想官方網(wǎng)站或授權(quán)平臺(tái),以避免潛在的安全風(fēng)險(xiǎn)。下載后,安裝過(guò)程簡(jiǎn)單快捷:首先運(yùn)行安裝文件,按照提示完成設(shè)置,然后啟動(dòng)軟件即可開(kāi)始使用。
該軟件的主要功能包括:
- 硬件檢測(cè):自動(dòng)掃描 CPU、內(nèi)存、硬盤等關(guān)鍵組件,識(shí)別故障或老化問(wèn)題。
- 性能評(píng)估:提供系統(tǒng)運(yùn)行速度、溫度監(jiān)控等報(bào)告,幫助優(yōu)化電腦性能。
- 驅(qū)動(dòng)更新:檢查并推薦最新的驅(qū)動(dòng)程序,確保硬件兼容性。
- 錯(cuò)誤修復(fù):診斷常見(jiàn)系統(tǒng)錯(cuò)誤,并提供解決方案,減少藍(lán)屏或崩潰風(fēng)險(xiǎn)。
使用聯(lián)想電腦檢測(cè)軟件,用戶可以輕松維護(hù)電腦健康,延長(zhǎng)設(shè)備壽命。建議定期運(yùn)行檢測(cè),以預(yù)防潛在問(wèn)題。請(qǐng)注意,僅從官方渠道下載軟件,避免惡意軟件感染。如需技術(shù)支持,可訪問(wèn)聯(lián)想客服頁(yè)面獲取更多幫助。