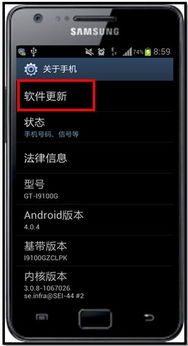
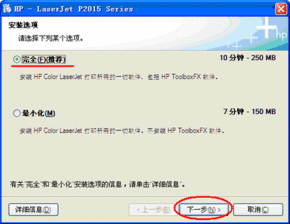
近年來,手機(jī)和電腦軟件行業(yè)持續(xù)快速發(fā)展,跨平臺(tái)融合與安全挑戰(zhàn)成為兩大核心趨勢。一方面,隨著5G和云計(jì)算技術(shù)的普及,手機(jī)和電腦軟件的界限日益模糊。例如,微軟的Windows系統(tǒng)與安卓應(yīng)用兼容性增強(qiáng),蘋果的Mac和iPhone生態(tài)通過Continuity功能無縫連接,用戶可在不同設(shè)備間同步工作和數(shù)據(jù)。同時(shí),云軟件如Office 365和Google Workspace的普及,推動(dòng)了移動(dòng)和桌面體驗(yàn)的統(tǒng)一化。另一方面,軟件安全面臨嚴(yán)峻挑戰(zhàn)。手機(jī)端,惡意應(yīng)用和隱私泄露事件頻發(fā),如某些免費(fèi)軟件暗中收集用戶數(shù)據(jù);電腦端,勒索軟件和網(wǎng)絡(luò)釣魚攻擊增加,尤其是在遠(yuǎn)程辦公場景下。政府和行業(yè)組織正加強(qiáng)監(jiān)管,推動(dòng)軟件透明度和加密標(biāo)準(zhǔn)。總體而言,手機(jī)和電腦軟件的創(chuàng)新不僅提升了用戶體驗(yàn),也要求用戶和企業(yè)更注重?cái)?shù)據(jù)保護(hù)。未來,人工智能驅(qū)動(dòng)的個(gè)性化軟件和物聯(lián)網(wǎng)整合將進(jìn)一步重塑這一領(lǐng)域。
手機(jī)與電腦軟件行業(yè)動(dòng)態(tài) 跨平臺(tái)融合與安全挑戰(zhàn)

如若轉(zhuǎn)載,請注明出處:http://www.ppip.com.cn/product/19.html
更新時(shí)間:2026-06-19 07:31:01
產(chǎn)品列表
PRODUCT
----------------